Javascript Regrets
Since 2014, I’ve worked in digital preservation, building a large-scale distributed digital repository where a number of US universities can preserve valuable digital materials.
In most of these universities, the library is responsible for digital preservation, and most libraries are understaffed. Many also have high turnover among their digital preservation staff, which means institutional knowledge is regularly walking out the door.
Small staff and high turnover lead to a big problem: libraries often don’t have the staff or the skill to manage all of their digital preservation responsibilities.
We saw the effects of this in practice. Though we had built the preservation system everyone had asked for, only a handful of organizations were actually using it. When we talked to the ones who weren’t using it, they cited three big reasons for not using it:
- lack of staff
- lack of technical expertise
- lack of time to develop the preservation workflows that would push materials into our repository
To be clear, these organizations do have technical expertise, but they’re stetched so thin, they can’t always spare it for digital preservation. It may take six weeks of dedicated work to design and build a preservation workflow, but no one in the organization has six weeks to spare in any given year.
To solve these problems, I built a program called DART, which makes it easy to define, test, and replicate workflows. DART will package up digital materials in the Library of Congress’ standard BagIt format and ship them off to a remote repository.
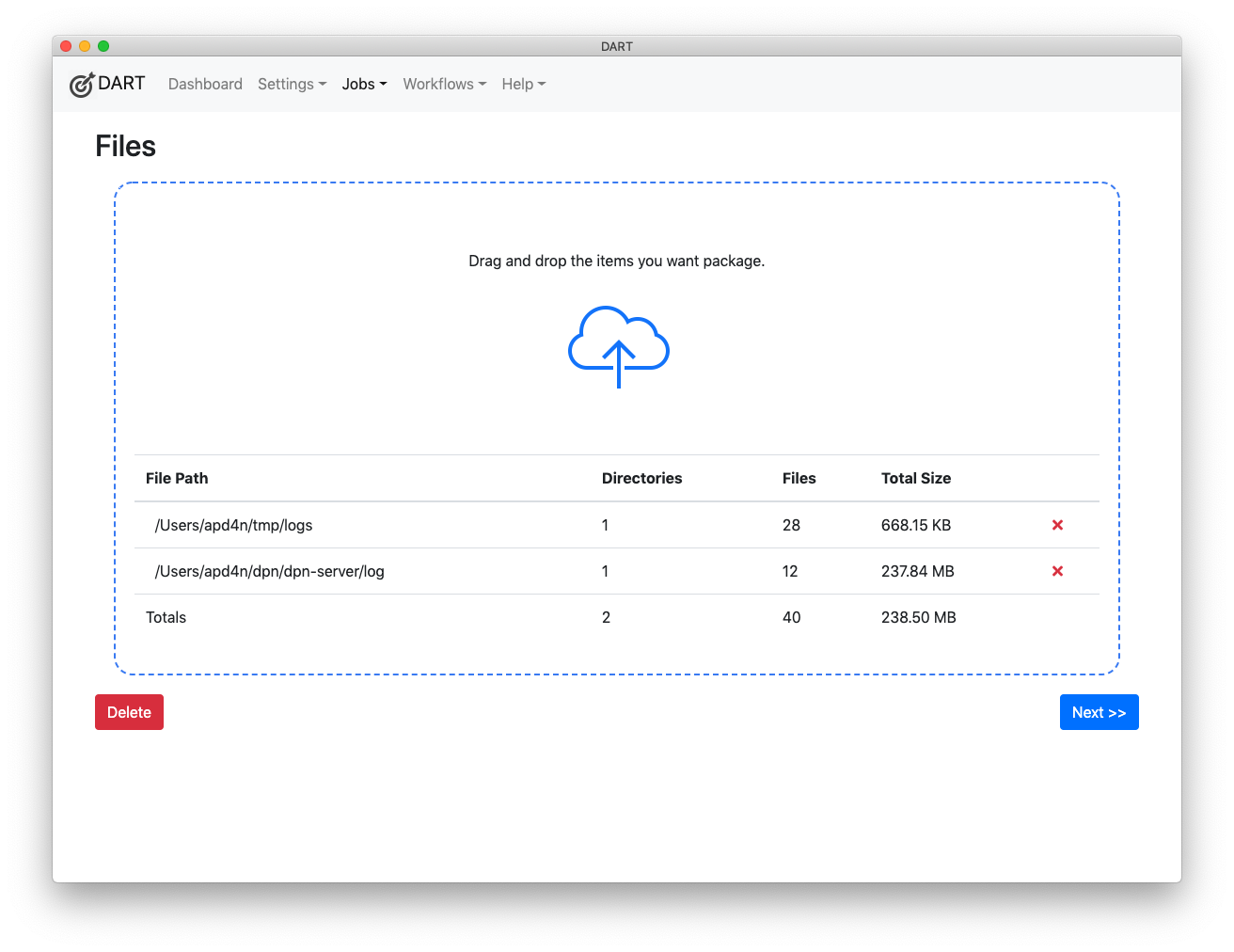
Users can define and test the inital workflow with a simple point-and-click interface, add files with drag-and-drop, and then watch the process run. Once they get a working process (which may take 30 minutes), they can save it as a workflow, and then run all of their materials through that workflow. Workflows can even be scripted and run unattended.
It took a few years for DART to gain traction, but now a number of organizations in the US and Europe are using it.
When I started working on DART, I was looking for a technology with the following features:
- It had to be cross-platform, since the preservation community uses Windows, Mac and Linux.
- It had to have a friendly UI.
- It had to support drag-and-drop, since this was something everyone understood.
- It had to provide full access to the underlying filesystem for technical reasons having to do with packaging and workflows.
I evaluated a number of technologies and ultimately settled on Electron, because at the time, it was the only reasonably mature technology that ticked all the boxes.
DART is an open-source app with a plugin architecture. I wrote it that way because I knew there were organizations out there with special needs, and I wanted them to be able contribute the features they needed without having to understand DART’s complicated innards.
Fast forward a few years, and DART has a plenty of users. Depositors who had not pushed materials into our preservation system pre-DART now contribute regularly. Outside organizations use it all the time in ways I never thought of. And people regularly ask for features.
What I didn’t know about Electron when I chose it was what a nightmare maintenance would be. I regularly get Dependabot alerts warning me of critical vulnerabilities in underlying npm libraries. When I try to upgrade them, I get errors. Some of the errors are related to breaking changes, some to library version incompatibilities.
Often, npm’s way of handling version incompatibility is to include several versions of a library, with each used in a different context. Try debugging that. On top of all this, many of these underlying libraries have unreadable code, no comments, no documentation and no tests. Many are abandoned.
As a lead developer, I would not permit developers on my team to write code that’s unnecessarily difficult to reason through, because that code isn’t maintainable. I wouldn’t permit uncommented, undocumented, untested code. Nor would I permit huge chunks of potentially dead code in the codebase–especially without tests and coverage reports–because maintainers can never be sure how that code factors into the application or whether it’s safe to touch it.
Many Node libraries that are well maintained and well documented rely on dozens of underlying libraries that are not. Some even rely on abandoned libraries. As soon as you start using Electron and Node, you introduce a massive amount of technical debt into your project, and you will pay for that for years.
A fresh project should start with zero technical debt.
It’s not just the quality of underlying libraries that makes Node/Electron apps difficult to maintain, it’s the quantity. DART has 45 explicit npm dependencies. These, in turn, pull in over 600 other dependencies.
Compare that to our more feature-rich Golang apps. They often have 12-20 explicit dependencies, which in turn may pull in 20-30 others. That’s an order of magnitude fewer dependencies. All of them are at least minimally documented, and all have test suites.
Your language and libraries are your foundation, and the JavaScript ecosystem is a foundation of sand. Build on top of it, and your structure will be unstable before the year is out.

When I tried to keep DART fully up to date with Dependabot’s security warnings and the latest versions of Electron, I sometimes spent twenty hours a month just debugging and fixing features that had worked flawlessly for years. We run a very small team and cannot spare that amount of time for work that essentially buys us nothing. We would much rather spend those twenty hours improving products and adding features.
JavaScript has a number of other shortcomings, including a lack of tooling standardization (node modules, ES6 modules, babel, webpack, RequireJS, npm, yarn, grunt, gulp, etc.). In JavaScript, more than in any other language, I find myself fighting against the tooling or trying to decipher error messages from tools that, in languages like Go, Ruby and Python, rarely get in my way.
A bigger problem, however, is the language itself, which, in the Node world anyway, forces an async model even where it doesn’t belong.
For example, DART creates tar files, and tar files must be written one file at a time, in order. NPM’s tar-stream package effectively requires you to use npm’s async queue to ensure that files are written one at a time. async queue requires you to define event handlers for things that might happen in the queue, such as expected and unexpected draining of the queue.
Exactly when anything happens in the tar-writing process is anyone’s guess. In a JavaScript app, every function is doing it’s own thing, all the time, and throwing out messages now and then to tell anyone who’s listening what it just did.
The human mind was not built to reason this way. We don’t have conversations where everyone is shouting at once. We take turns, because our minds are conditioned to think chronologically.
While async programming makes sense in certain contexts, it’s not a one-size-fits-all solution. It’s great for UIs, where users can click anything at any time. It’s also great for network-heavy apps in which network calls will complete in unknown times and unknown order.
However, the event-based model is not suited for applications that require most or all instructions to complete in chronological order. The use of async queue (and Promise.then, for that matter) to enforce chronological ordering adds cognitive load for new developers trying to contribute to an existing codebase.
Even IDEs can’t trace the whole cascade of events triggering other events unless you run your code in debug mode with breakpoints all over the place. That’s a slow, tedious process, and it’s easy for developers to foget the flow as soon as they close the debugging session.
Compare this to non-evented code–especially in statically-typed languages–where the IDE lets you analyze the code without running it. Where you see a function call, you can jump to the definition and inspect it. The code itself is the record of what’s being done.
The upshot of this complexity is that outside developers who have wanted to contribute to DART have not been able to. Every one of them has given up, and for a project whose goal was to allow others to contribute the features they need, that’s a 100% failure rate.
I can’t blame those developers. When I have to fix DART or add a feature, it can take me hours to understand code I wrote a year ago. This very problem was the reason I stopped using Perl in the early 2000s. (And, by the way, I do not have this problem when I read my old Ruby, Python, or Go code.)
Perl was as convenient as JavaScript. You could write a functioning app in no time, and it would run just about anywhere.
But once you get to a certain level of complexity, once your codebase passes a dozen or so files, you start feeling the pain of a language that wasn’t designed for complex apps and large-scale systems. You find yourself in the classic devil’s bargain, in which the promise of a quick-and-easy start comes at a heavy long-term cost.
I’ve implemented some of DART’s features elsewhere in our codebase using Go, and the difference in implementations is stark. The Go code is more compact, much more clear, easier to maintain, has far fewer dependencies, and is vastly easier to debug. Over the years, it’s required little to no maintenance.
Systems-level languages are the spouse who lays out the rules up front and then rewards you with reliability and consistency so long as you abide by them. JavaScript is the seductive one-night stand that leaves you with an STD and an unwanted pregnancy.
So where do we stand with DART, Electron and Node?
DART was meant to be easy to use, and it is. It was meant to get people past workflow barriers that had impeded their work for years, and it has succeeded in that.
It was meant to be maintainable, and it’s not. It was meant to allow external contributors to add features, and despite being as cleanly-coded as JavaScript will allow and as thoroughly documented as possible, it’s failed.
So I’m going to rewrite the app using Wails, which provides the same cross-platform support as Electron, with less heft and fewer breaking changes. I can port most of the UI code from the Electron app, while ditching all 650 Node dependencies. (The UI works just fine using vanilla JavaScript, HTML and CSS.)
Then I can pull in existing Go code from other projects.
This may take me a few months, but it will relieve me and the community of massive technical debt and years of maintenance busywork. The project will be more maintainable and easier to contribute to. And that, in turn, can make it more useful to the broader community.
So long, JavaScript!